Introducing Flip AI System of Intelligent Actors

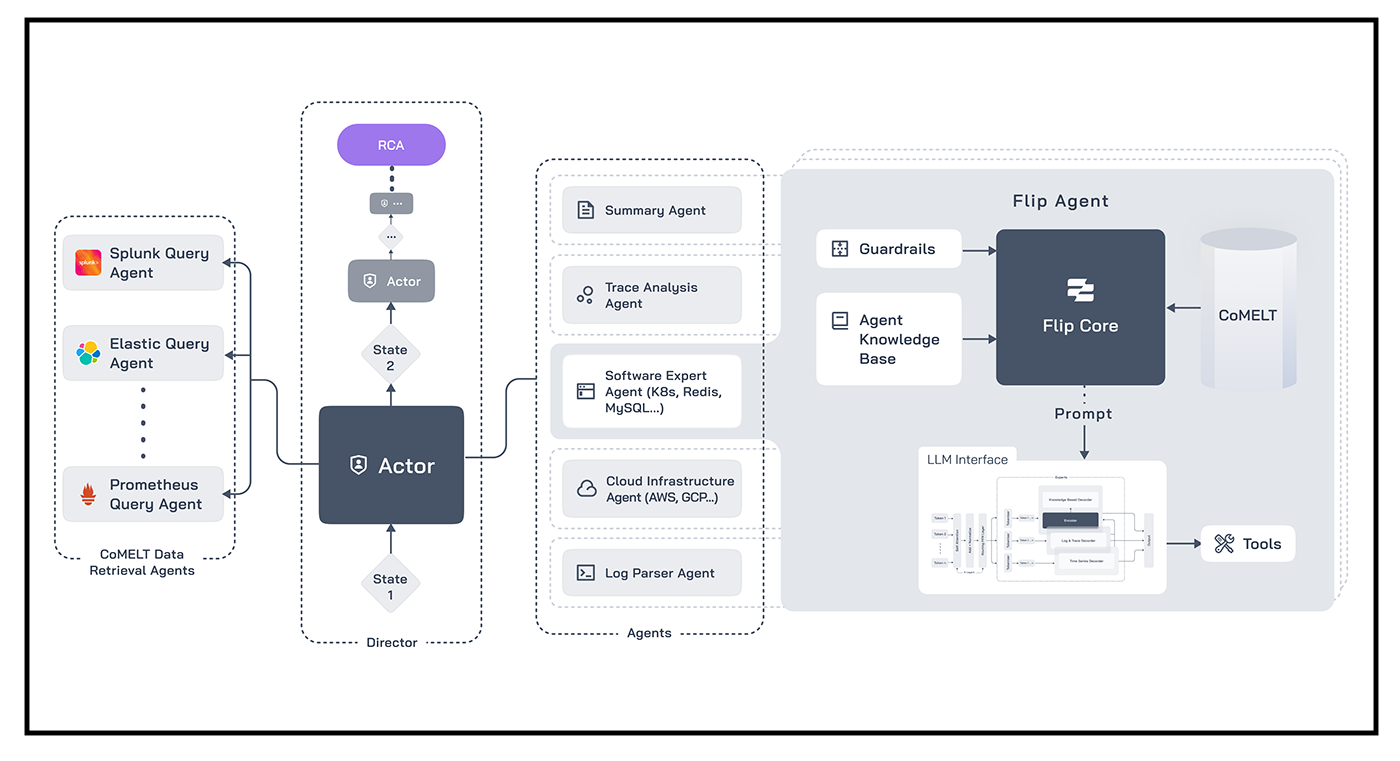
Today, we are proud to officially introduce to the world the Flip DevOps LLM, the world’s most powerful AI model for devops, incident debugging and observability. Incident debugging is a complex and often multi-step process involving several tools and experts. To mimic this process, Flip AI developed an LLM orchestration framework which we refer to as “System of Intelligent Actors”. This novel and innovative approach is akin to subject matter experts coordinating together to query observability systems, and then reasoning through the observability data in order to connect the dots to synthesize the potential root cause of an incident. Based on extensive benchmarks that include real world production incidents, we find that Flip DevOps LLM is able to debug production incidents in complex production environments with high accuracy in under a minute. Additionally, on several internal benchmarks, Flip DevOps LLM is 67.6% better than the best general open source Mixture-of-Experts (or “MoE”) Mixtral model, and 34.5% better than GPT-4.
Attached to this blog post is a detailed technical report, System of Intelligent Actors: The DevOps Chapter, discussing how the Flip AI System of Intelligent Actors helps in debugging production incidents at scale.
Collectively, the team at Flip AI has developed and managed some of the most large-scale software systems in the world. We have modernized the entire entrance processing application stack for the largest military (by budget) in the world. We have built machine learning models to calibrate virus transmissions and determine warehouse resourcing levels during the COVID-19 pandemic for one of the largest retailers in the world. We built a tier-1 managed large language model service, maintained at five 9s of reliability, for one of the world’s largest hyperscaler clouds. At heart, we are technologists, and if there’s one reality we have all grappled with (somewhat begrudgingly we might add!) it’s this: all software systems will eventually break. It may or may not be catastrophic. It could be a tiny crack in the dam, or it could be something more. It could be something benign, or a harbinger of darker days ahead. The point is, as software developers, DevOps engineers, site reliability engineers (SREs) and other technologists, we are all too familiar with the seemingly brittle nature of software systems. Yet we bravely march on, knowing that just around the corner lurks that 2AM page, that cacophonous war room chatter, or that flurry of system alerts.
Problem: Debugging Ain’t Easy
The complexity in building and maintaining software has only increased over time. There is an ever increasing number of components in the modern software stack - for example, microservices-oriented architectures, container orchestration, hybrid cloud architectures, messaging queues, etc. The permutations of what could go wrong has increased exponentially. Yet the evolution of observability platforms over the last 20 years has mostly been about storing and querying ever-increasing amounts of data (and costing customers huge sums of money in the process). Despite these huge investments in observability (both in terms of time and money) a step-function increase in debugging ease and efficiency had not yet happened - until now.
For the past three decades, it has become common and best practice to instrument software systems such that they emit telemetry data, signals that can help a technologist determine whether a system is in good health or not. This data is sometimes referred to by the acronym MELT (Metrics, Events, Logs, Traces). Most developers will also look at code bases as a part of their investigation of incidents, leading us to modify the acronym to “CoMELT”. This telemetry is then piped to an observability system, of which there are many, each with their own perceived unique value proposition. Many of our customers call out that observability tools have been reduced to expensive big data storage and retrieval systems, all of which have their own unique, arcane query syntaxes and quirks that lock in your data. Flip DevOps LLM is completely agnostic, and integrates with a majority of the observability tools in read-only mode and is able to harmonize, synthesize, rationalize and interpret any and all underlying CoMELT data to produce the incident root cause analysis report.
Next Generation Capability
Under the hood, the System of Intelligent Actors framework is powered by Flip DevOps LLM, which is based on MoE architecture.
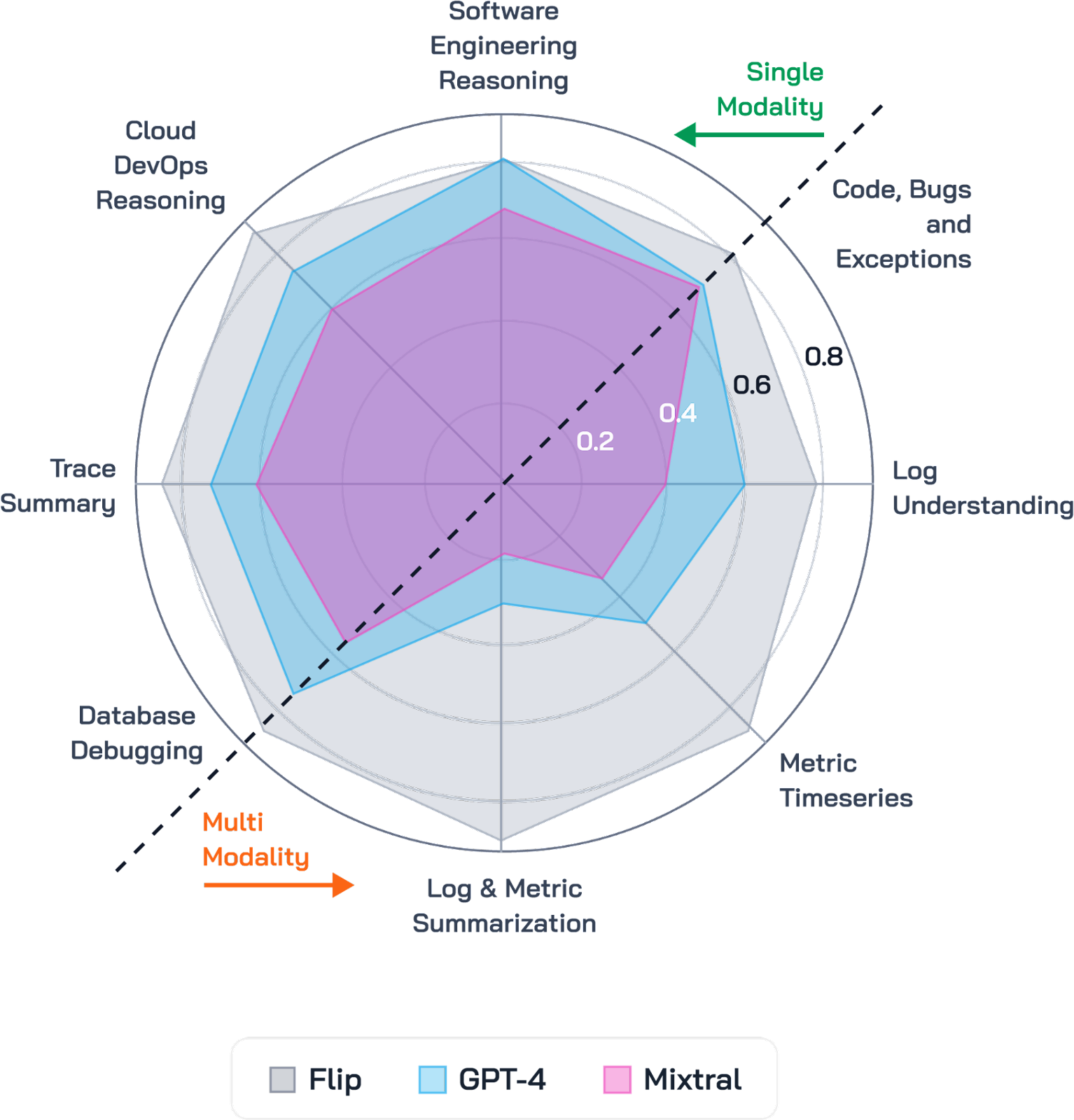
We conduct rigorous evaluations of our model across more than 30 different tasks that span all of CoMELT modalities and several combinations of these modalities. For ease of reading, we aggregate the tasks into logical categories that reflect the expert human debugging personas in an incident debugging war room. For baselines, we use Mixtral, the most popular MoE model and GPT-4. The Flip DevOps LLM consistently outperforms Mixtral by an average of 67.6% and surpasses GPT-4 by 34.5% across various tasks, as detailed in Table 1. For tasks that require multiple pieces of evidence (multi-modal) to reason, i.e. Log Understanding, Log & Metric Summarization, Metric Timeseries, and Database Debugging, Flip’s models show a noticeable step-function improvement in performance.